Keys in Databases
There is an important aspect of relational databases that we have not yet touched upon. Namely, what is called keys.
The purpose of these keys is quite simply to give each entry in the database what amounts to a unique fingerprint. This helps us to identify these and distinguish them from other entries.
There are two types of keys we will look at here: what are called primary keys (PK) and foreign keys (FK).
What is a primary key?
To make relations work in databases—technically, in order to be able to look up and find data in a database—it is necessary to uniquely identify each instance in the entities.
Attributes can be used for this. But for an attribute to be used as a primary key, it must satisfy three requirements:
- It must be unique
- It cannot be empty (we call this a NULL value)
- It must never change
Unique attributes in an entity that meet these requirements are the entity’s candidate keys, and one of these is chosen as the primary key.
If there is no such attribute in the entity, one must be created—often in the form of a sequence number, such as a customer number in a store, or a personal number related to citizenship.
This becomes easier to understand through an example. We can return to the earlier example of citizens and passports.
One-to-one: Citizen and passport
A passport number is unique, cannot be null, and does not change. It can therefore be used as a primary key. This is practically a separate column that we insert into this entity, which is unique for each row of data.
The passport number can be used here as a primary key for the passport itself—but not for the citizen. We remember that this cardinality is not mandatory (the citizen does not have to have a passport).
In this simple example, we have only one attribute in the citizen entity, namely the name. It might seem logical to use the name as the primary key, but it’s not possible. Several people can have the same name, and it is possible to change names in the course of life.

We therefore expand the citizen entity with a national identity number —which is unique, never null, and impossible to change.
We then expand the entities with a column for keys, and use the national identity number and passport number, respectively, as the primary key.
The key to creating relationships
We have now created a primary key for each entity. But how do we actually connect these with a relationship?
For this, we do something called key migration. We move the PK (in this case, the national identity number) from the citizen entity to the passport entity, where we name it foreign key (FK).
To be clear: The passport already has its own primary key (passport number), but we also add a foreign key (the citizen’s national identity number, the primary key of this other entity). In this way, we can see very clearly who the passport belongs to.
This is what makes it possible to follow relationships between instances of entities; in this case, which passport belongs to which person.

In one-to-one relationships, it is quite possible that these keys can migrate in both directions. But since not all people have a passport, but all people who have a passport have a personal number, it is logical to just migrate the national identity. It will then never be able to be null under the citizen.
One-to-many: Person and book
Let’s look at another example, namely the one-to-many relationship where a person can own 0, 1, or many books.
Neither person nor book have attributes that are unique. Books as well as people can have the same name—and names can change. We also note that there can be zero books attached to a person.
As it stands, therefore, we have no candidates for keys.

This means we need to find and introduce attributes that uniquely identify these two entities. We resolve this by extending the person entity with what we call p-ID.
We could have used the national identity number, but if this is a bookstore, a book club, or a website where one can register books and discuss them with other enthusiasts, we avoid using such sensitive data. Instead, we simply get the database to generate a unique ID for each person who registers. It’s a matter of privacy.
This is an example of what we can call synthetic attributes. We can generate these ourselves, or the database can auto-generate them. The first person can be number 1, the next is number 2, and so on.
The book already has a unique attribute, namely the ISBN number that all books published in the world receive. It is a unique number and it never changes. The ISBN number is publicly available information, and can be used as it is.
Similar to the example with citizenship and passport, we move the person’s ID over to the book, and use it as a foreign key. Then it becomes possible to list all books that have that person ID in them as a foreign key—or in other words, to find all the books owned by the person.
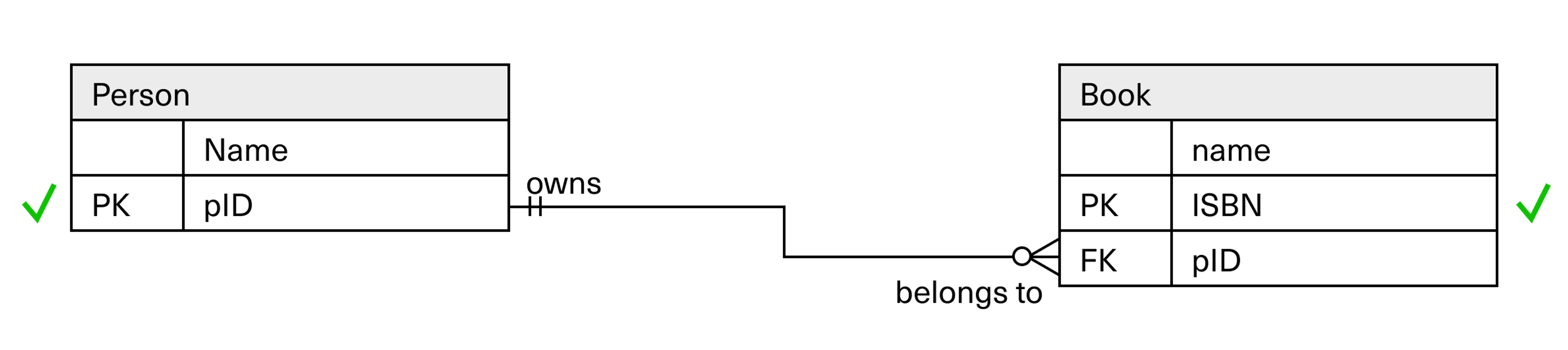
In one-to-many relationships, the keys must move from the one-side to the many-side, and be used as a foreign key there.
If the key migration went the other way, it would generate a long and indefinite series of foreign keys—in this case hundreds, perhaps thousands of ISBN numbers—inside the person entity. This is not what we want, and this is not how relational databases should work.
We want only one instance of a key under each instance in the entity.
Many-to-many: Consumer and recycling point
If we can’t move a bunch of keys into another entity... what then with many-to-many relationships? Good question, attentive reader!
There is a solution, and to show it we can look at the example of the consumer and the recycling point.
Neither consumer nor recycling point have attributes that are unique. In the recycling point entity, we have added type as an attribute, but we can’t use type as the primary key, as there are many points with the same type.

Here, by the way—and this is a small digression from the example—we see that type should be separated into its own entity. Attribute data such as “paper and cardboard”, “plastic”, “glass and metal” and so on are common to many points, just as a postcode is a common attribute of many street addresses. As you remember, we want to avoid redundancy and errors in the database, and therefore these should be created as separate entities.
Anyway, back to the keys: For the consumer entity, we create what we call a cID, consumer ID.
This can be system-generated, or it could be a unique customer number. Again, we want to avoid using the national identity number, considering privacy. The unique ID of the recycling point, we call rID.

But in this example—where should the keys go?
Should we take all the consumers who use a recycling point and put them under the recycling entity? That’s not possible. That would result in potentially a huge number of repeated consumers. For the same reason, we can’t take the key from all the recycling points a consumer has used, and put it under that entity.
In many-to-many relationships, the keys cannot directly migrate from any of the sides to the other. In our example, this would result in repetition of all consumers or all points, and we can’t do that. But we have a solution to that in relational databases.
The solution is to add a new entity, which we put between the two. We call this a resolution entity.
This entity represents a specific recycling event carried out by a consumer at a point at an exact time.
We allow the two primary keys (PK) to migrate as Foreign Key (FK) to the resolution entity, which we call recycling. A consumer can now carry out many recycling events, and many recycling events can be carried out at one recycling point. Here we also added a new attribute, time, and put it in the resolution entity.
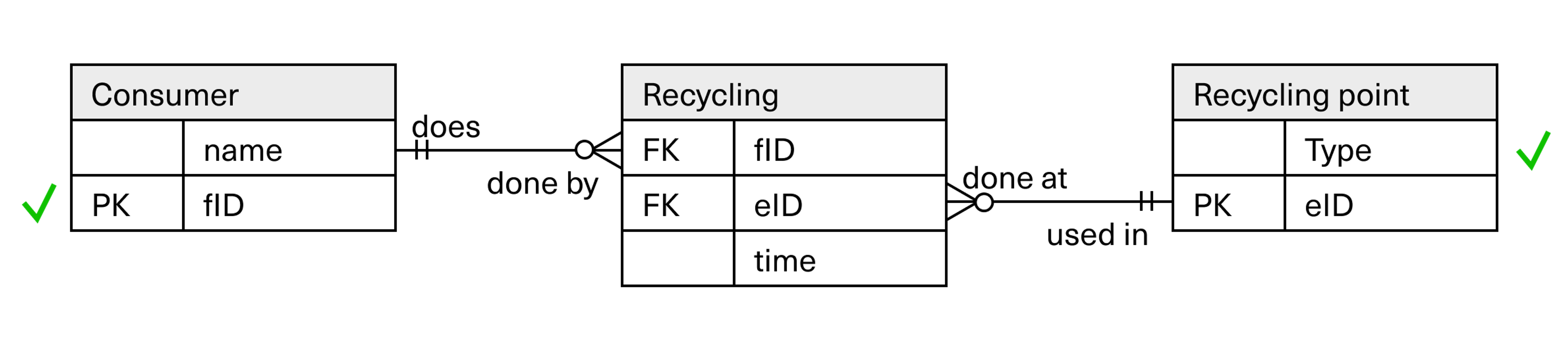
The resolution entity has no PK, it is uniquely identified with both FKs, one from each of the entities in the many-to-many relationship. The primary key of the resolution entity will therefore always be the combination of the two foreign keys that have migrated there from each side. The timestamp must also be included in the key, to avoid duplicates.
By making a query here now, we can see which recycling points (eID) were involved in a recycling where a consumer (fID) did a recycling. The combination of these two foreign keys will show a unique person who has put recycling material into a specific point at a specific time.
Phew! And with that, we suddenly have a pretty good understanding of how a database works. Not bad, right? With that, we will also round off the chapter, and move on to looking at how we can now actually use these structured data.