Relational Databases
Do you remember the example of mapping salary development and equality in a few IT companies?
This was a simple, small study—where Excel was a more than adequate tool. But if we were to scale this up to study a broader sample of the entire industry, then we would likely be in need of more powerful tools. More specifically, we would typically use some form of relational database.
You will become very familiar with what this is. Let’s start with a very simple example, to understand the utility and logic in all this.
The film collection
Suppose you’re old school, and have your own film collection. You have DVDs, Blu-Rays, and 4K films—even some old VHS tapes in the shed!—as well as films you have bought and own digitally on various services.
A simple spreadsheet won’t suffice to manage this collection; you need a database!
Why and how would you organise this, you ask?
Separating data from its storage structure, as we do in this setup, simplifies the process of making changes and updates without causing errors and other ripple effects.
Entities and attributes
In a relational database, data is grouped into what we call entities. Entities are logical units of data. They represent “something that exists”, be it physical, digital, or conceptual, about which data is being collected. Examples include “customers”, “treatments”, or “software".
When you work in a spreadsheet, the entity is typically what you call the sheet or tab itself.
Attributes are properties that can be associated with an entity. If for example, the entity is a list of customers in a business, the attributes would be the things that it is desirable to know about the person, such as a first name, last name and gender, and perhaps in some cases—in banking and insurance, for example—also details such as age and income.
In the spreadsheet, the attributes would typically be the name of each column.
Neither entities or attributes refer to the data itself—but rather to the way the data is structured. The actual data comes into play when we fill in the specific values for these attributes associated with each entity.
In this spreadsheet, the sheet would represent the entity (customers); here there are columns for different attributes (such as first name and last name), and under these, the data can be entered (Trym Trymsen and Siv Suveren).
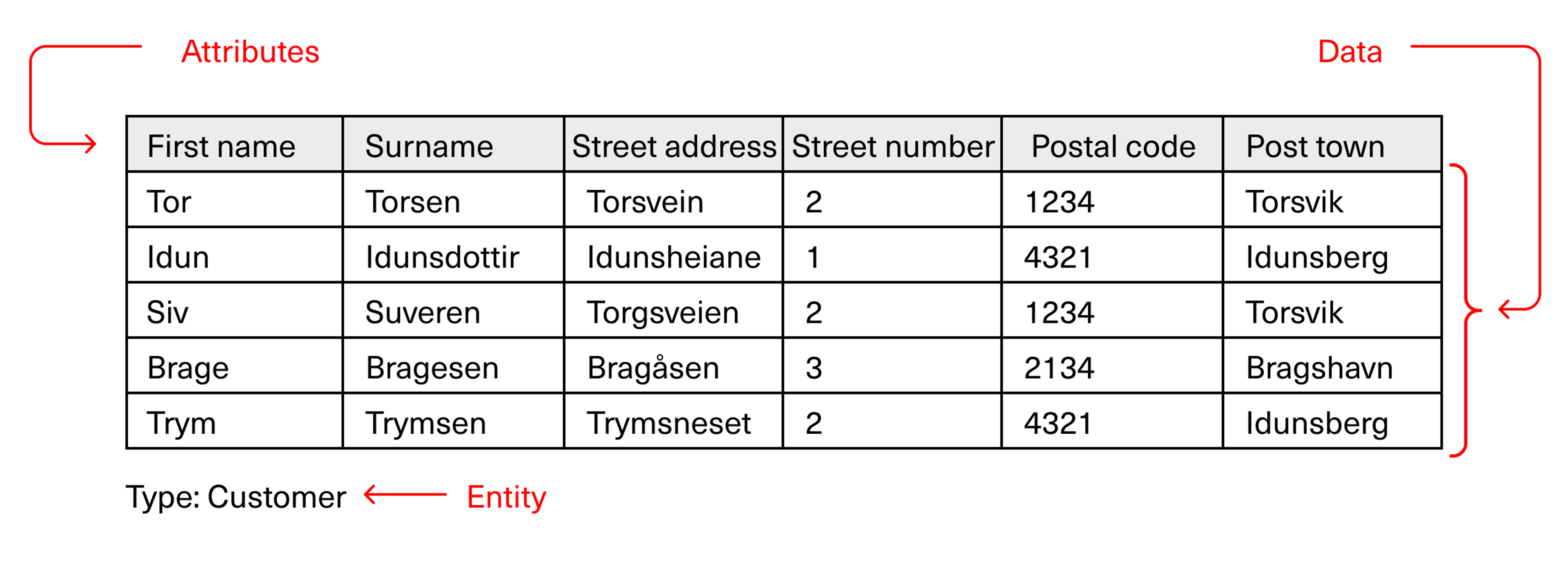
Another example of an entity could be books, registered with attributes such as the author’s name, the name of the work, publisher, ISBN, details about the edition, and more. Or the entity could be recycling points, with attributes such as type, location, capacity, and weight. In short, it can be anything!
Redundancy: When we store the same thing many times
If we look a little closer at the spreadsheet with the customer data, we notice some practical and logical things that are easy for us humans to understand, but which can cause trouble when this is read by a computer.
For example, we see that Tor and Siv have the same address, and that Idun and Trym share the same postcode and post town.
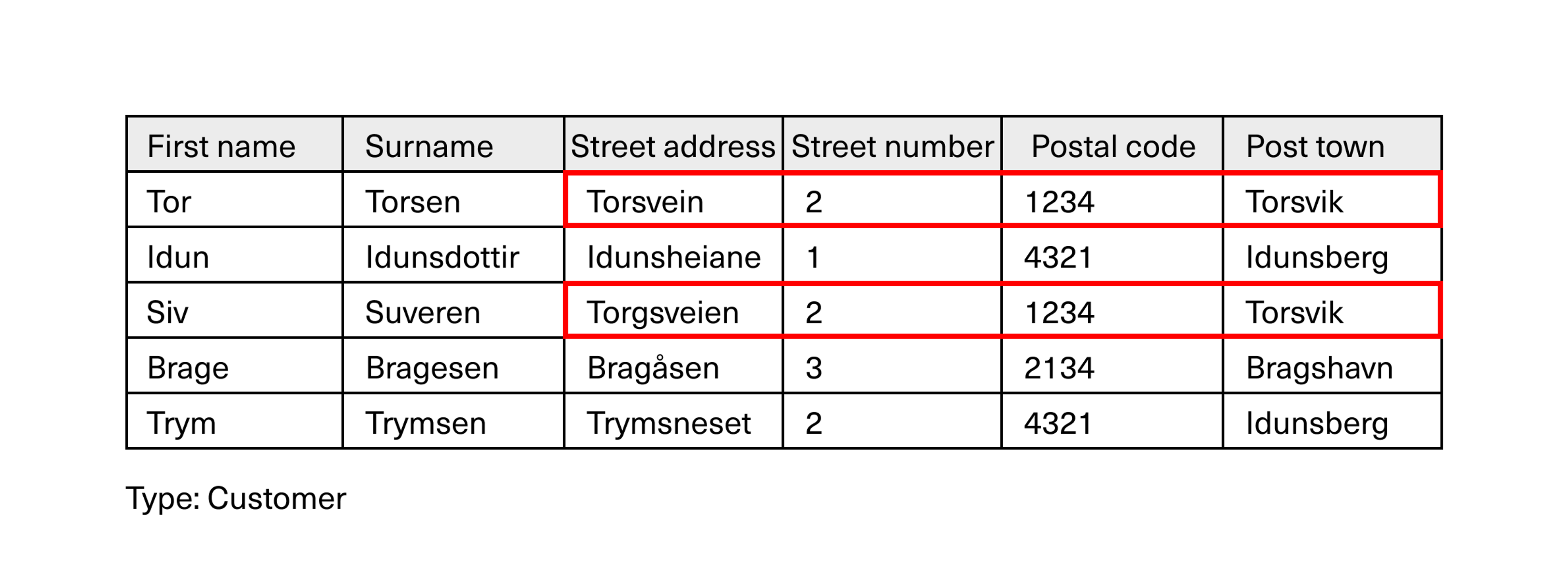
The way the spreadsheet is structured, the full address must be stored for both Tor and Siv. Also the postcode and post town must be repeated in the database for all customers living in the same place. This is called redundancy.
Redundancy is problematic for two reasons. Firstly, it is inefficient in terms of storage of the data itself, often in data centres consisting of a lot of hard drives, which require space, energy, and cooling.
Secondly, storing the same information twice can lead to mistakes in databases. This is because, whenever one piece of data changes, all related entries need to be updated immediately too. For instance, if the town of Idunsberg decides to change its name due to merging with another town, we’d need to update this for all customers living there.
It’s a lot harder to change several things at once than just one, and so the possibility of errors increases.
Additionally, people can move around; we don’t necessarily live in the same place our whole life. That’s why, in a database, we keep customer data and address data separate. This allows customers to change their address and lets us have more than one customer at the same address.
Insight
Data history
Another advantage of using relational databases—compared to, for example, a spreadsheet—is that it’s easier to keep a record of past data
Let’s say we have a person named Brage Bragesen in our database. He orders a new bathroom to be installed at his address. But later, Brage moves to a new place and orders another bathroom from the same company. The company updates his address in their system. But then, they can’t remember where they installed the first bathroom!
By separating logical data units such as people and addresses, we can make relational databases connect an order to a historical address, even if the customer changes their details.
Entity, attribute, and relation
Let’s go back to the entity in our relational database, for the last time in a spreadsheet version.
We will now dissolve the original customer entity and separate the address from it. So now, we’ll have one entity that includes the customer’s first and last name, and another one for the addresses.
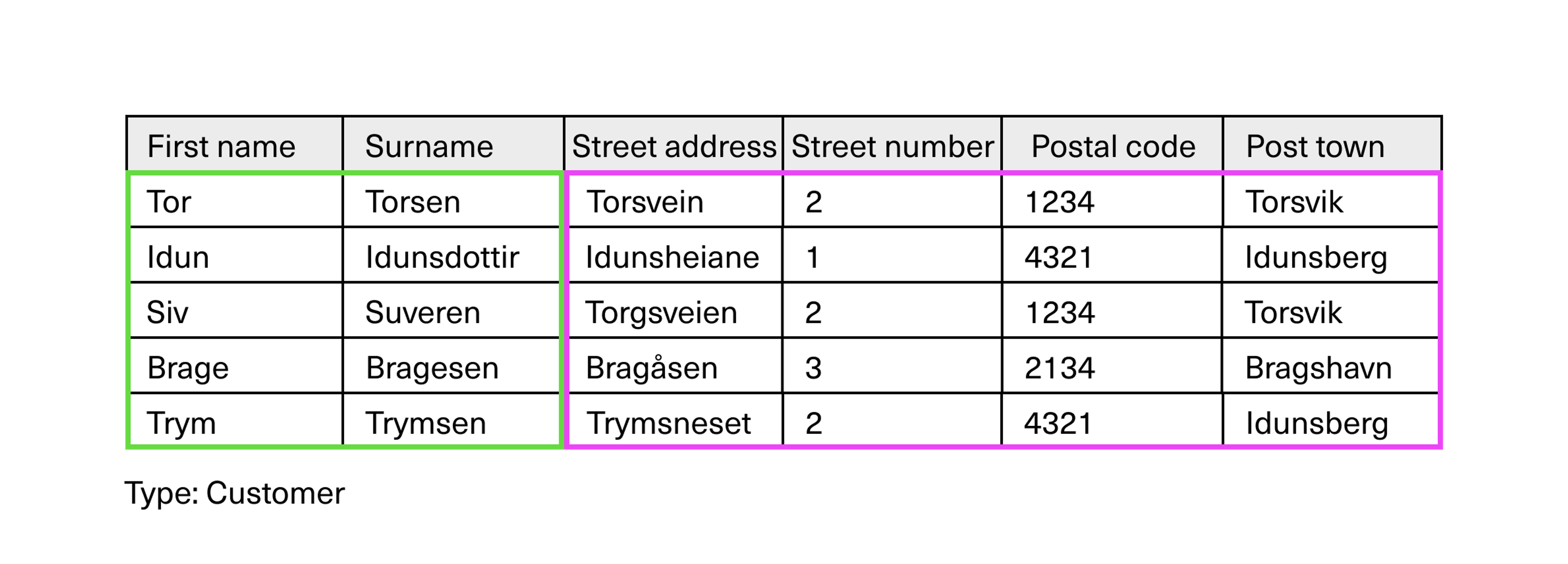
Addresses can instead be linked to customers by establishing a relation. Changes made to an address will then be reflected for all customers who have this address, even if we only change the address in one single place.
This is one of the principles underlying relational database modelling, something we call EAR modelling (for Entity, Attribute, and Relation).
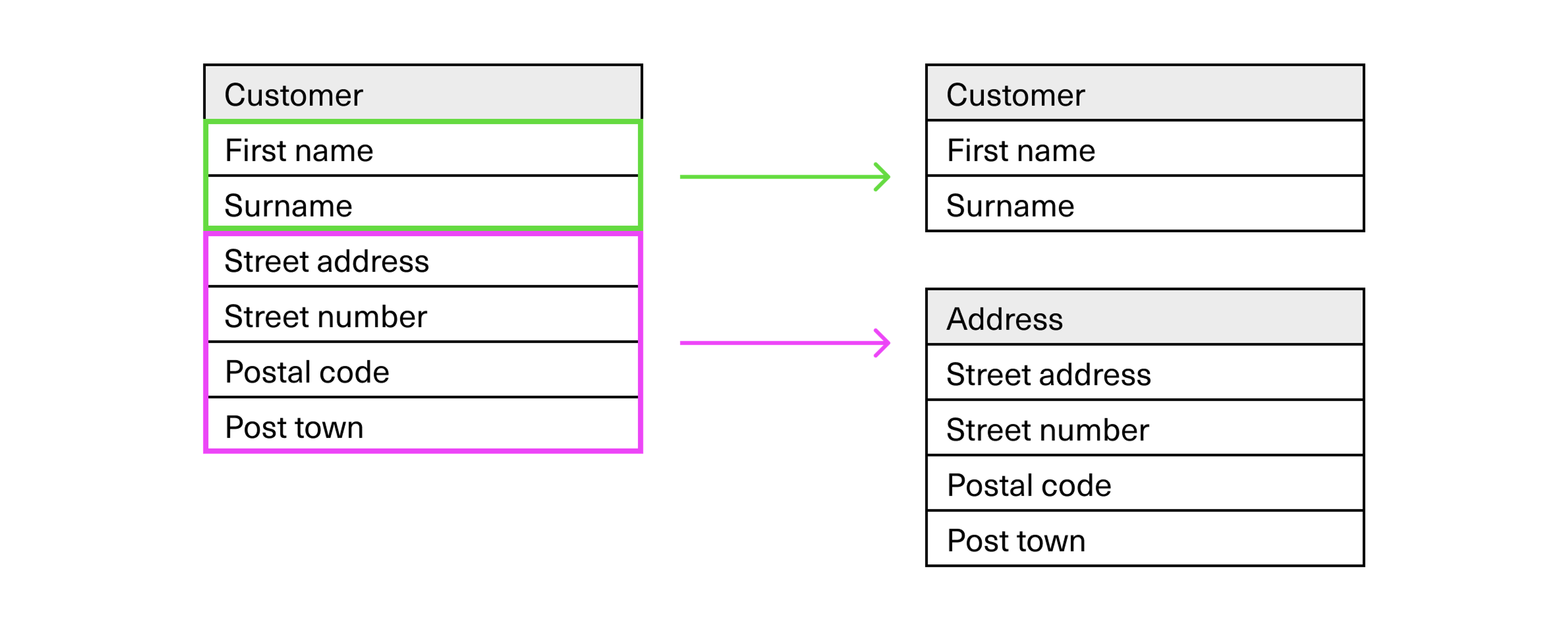
However, we still have different street addresses in the same post town. So to avoid having to register the same postcode and the same post town again for every single street address located in the same place, we can also separate this. We separate out yet another new entity:

These are good principles for how to work with relational databases. Customers live at addresses, and addresses belong to post towns.
So far, we have talked about entities and attributes, as well as data stored in relational databases. However, our database does not yet tell us anything about who lives at which address, or which address belongs to which post town.
Such look-ups are made through relations between the entities, where the attributes serve as keys for look-ups. It is this structure with relations and keys that has given the name relational databases.
What is meant by relations, and how this works, we will go on to explain in the next topic.