Artificially Intelligent Systems
Artificial Intelligence (AI) is something everyone has heard of, though it can still be challenging to define. (What is intelligence, for that matter?)
Our thoughts quickly turn to social media, where many are aware that AI is used—and perhaps suspect that we are somehow being manipulated in one way or another.
Simultaneously, we also have the popular cultural depiction of AI in films like The Terminator, Blade Runner and Star Wars. Here, AI is represented as a robot or a computer system with human-like intelligence—capable of thinking and acting independently to match, and perhaps exceed, our own mental abilities.
Does Instagram and TikTok's algorithms have anything to do with C3PO or Skynet? Realistically speaking, what exactly is artificial intelligence anyway?
Systems that achieve a goal based on data
Artificial intelligence is simply an umbrella term. The same way apples and pears are both fruits, two different computer programs can both be considered as examples of artificial intelligence, even if they do widely different things and are based on different underlying techniques.
A common understanding of artificial intelligence is as computer systems or programs that can receive and process data from various sources and—with some degree of independence—carry out actions that maximise the chances of achieving a given goal.
Norway's national strategy for artificial intelligence has the following definition: “AI systems act in the physical or digital dimension by perceiving their environment, processing and interpreting information and deciding the best action(s) to take to achieve the given goal. Some AI systems can adapt their behaviour by analysing how the environment is affected by their previous actions.”
When you hear about artificial intelligence relating to technology and data, quite often it is more specifically machine learning that is being referenced. Machine learning is one of several subcategories of artificial intelligence, and encompasses systems that can learn from data.
What is machine learning?
You have learned what algorithms are, and we have written that some algorithms are referred to as “smart”; they are used to train and run machine learning models. Let's see what this actually means.
Algorithms underpin every computer program. Machine learning algorithms, too, rely on precise step-by-step instructions for what should happen in a particular situation; even though we call it “artificial intelligence”, there is no reflection, improvisation or self-awareness involved here.
Rather, it's about using mathematical and statistical methods and tools to make programs (called machine learning models) that can change and adapt their output depending on circumstances and available data.
First, we must determine the specific task the model is to solve—such as filtering out spam, playing chess, or predicting car sales in the coming months. The machine learning algorithm is then given specific data to work with—data used to “train” the model for the specific task.
To begin with, the model may not be able to differentiate between legitimate email and spam. But once it sees enough examples, and gets feedback on whether it is sorting them correctly, it will “learn” to spot the differences more precisely, and adapt to solve its task in increasingly better ways.
You can see how machine learning is problem-specific. A model can be trained to navigate a self-driving car in traffic, suggest the best route through traffic, review documentation for a loan application or automatically fill in fields on an invoice where it finds the necessary data. Each model is made to be as good as it can possibly be at its specific thing—but can't suddenly stop and decide to do something entirely different.
The Hollywood version of AI that resembles human intelligence is indeed something many people envision. This is called artificial general intelligence (AGI). But it is a vision that, as of writing, is far from achievable, and something entirely different from machine learning.
Example
Alien or Mamma Mia?
A typical example of how machine learning is used, is the recommendations you get from various streaming services. Here, machine learning models are used to suggest content based on what you like to watch or listen to.
Suppose you love science fiction but can’t stand frivolous romantic comedies. If you put on The Terminator one evening, and Blade Runner the next, the recommendation model of the streaming service can recognise a pattern and subsequently suggest that you put on, say, Alien or The Matrix—instead of filling your homepage with Mamma Mia and My Big Fat Greek Wedding, which you're not interested in.
In this example, the algorithm’s goal is to provide the best possible suggestions for content tailored to each user's preferences, habits, and tastes. The better the algorithm is made, and the more data it has to work with based on your and other users' habits and patterns of action, the better the algorithm can become at giving you suggestions you actually like.
The overarching goal is to maximise the chances of keeping you glued to the screen—and subsequently, continue to pay your subscription.
How the models are trained
There are many different types of machine learning algorithms, but it's common to group them into three categories: supervised learning, unsupervised learning, and reinforcement learning.
The simplest and most widespread of these is supervised learning, so we'll look at that first.
Supervised learning
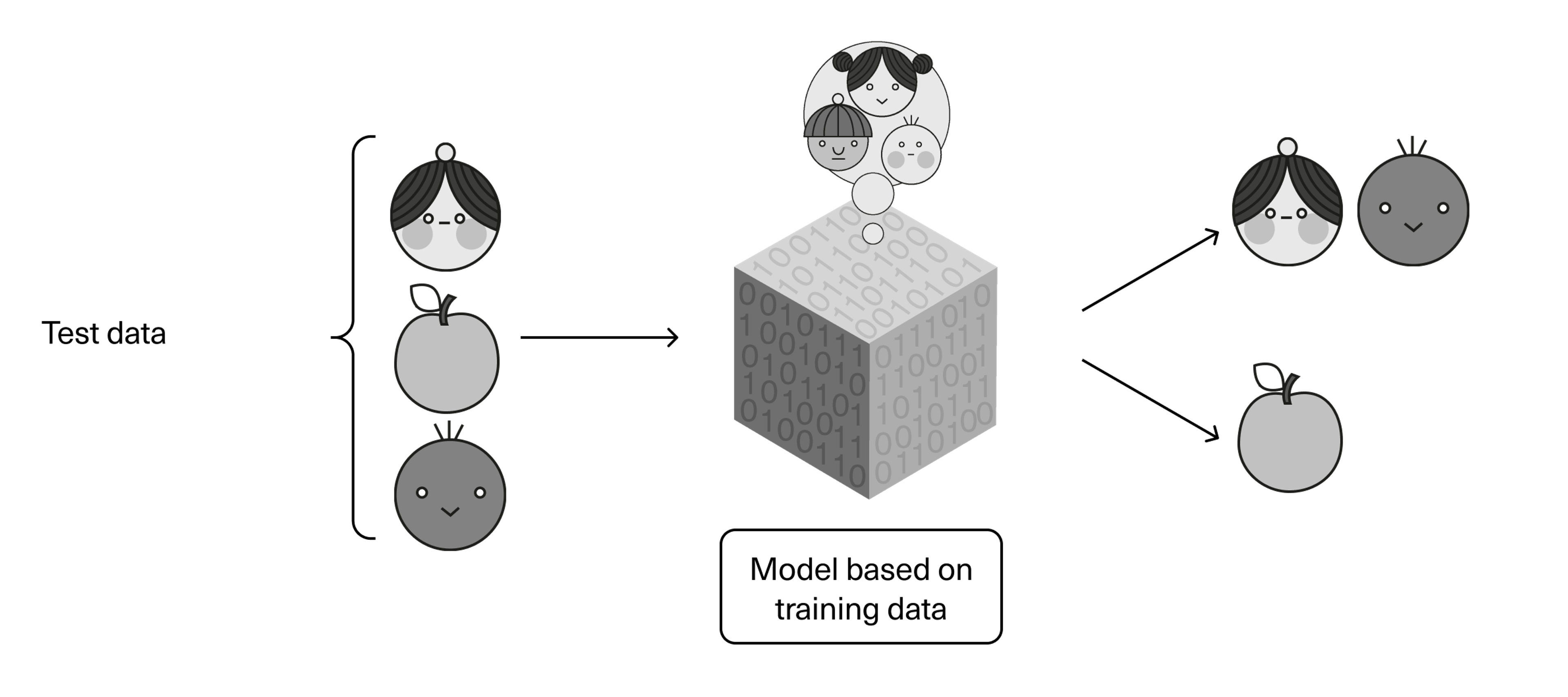
When training the machine learning model, we use what we call training data. If, for example, we're talking about a model to filter out spam mail, the training data can consist of tens of thousands, perhaps millions of examples of emails—both legitimate and spam—that the model should learn to distinguish between.
In supervised learning, the algorithm is given a dataset that contains both the data (input) and information about what each data represents (output). The algorithm thus has the “answers” to what spam is and what it isn't. The model should learn a rule that determines how new inputs (real data) are linked to possible outputs.
Another example: Imagine we’re training an image recognition model to differentiate between elephants and giraffes. As training data we would give it a plethora of images depicting the two animals. The algorithm holds the answers to which images are of elephants and which are of giraffes. The model—the program that is trained—can then get instant feedback and adjust its parameters as it learns to spot the difference.
Once the training is complete, test data—data the model hasn't seen before—is used to see how accurate it has actually become. Here we will use completely new and previously unseen pictures of elephants and giraffes, that were not part of the training. Thus, when we test the model with a new dataset, we will be able to tell if it has learned what it should have, and if it works as desired.
When the model is later put into production—that is, taken into real use, in this case an image recognition software—we can enable it to continue learning from the new data and develop further. However, this needs to be monitored to ensure that the model is actually improving and not learning the wrong things.

Unsupervised learning
In unsupervised learning, the algorithm looks for structures and patterns in the data on its own. Unlike supervised learning, no information about what the data means (output) is given during training. Instead, we want the model itself to recognise grey animals with trunks and strange yellow animals with long necks as different animals, and group them separately.
Reinforcement learning
Here the algorithm is not instructed on how to solve its task, but instead receives rewards and punishments for good and bad results. A typical example is a machine that is only given a goal—say, to win at chess—but is not told which pieces are the most valuable or what is considered a smart move. It then attempts to achieve this goal through trial and error.
With machine learning as a tool, we can solve problems in new and different ways, including things that we humans are not capable of on our own. This opens up many exciting possibilities. However, the algorithms are at the mercy of the data they have to work with.
Enough data—and good enough data—are therefore prerequisites for succeeding with machine learning.
Data is increasingly in abundance, and it comes from all kinds of sources. This is partly as a result of the Internet of Things (IoT), which is the next thing we will look at. Later, we will also revisit artificial intelligence and machine learning, in chapter 5.