Machine Learning
Do you remember what machine learning is? We start with a little reminder:
Machine learning (ML) is a subset of artificial intelligence where algorithms learn patterns from data. Instead of being explicitly programmed to perform a specific task, these algorithms improve their performance based on experience. In essence, ML trains a model on a set of data, and this model can then make predictions or decisions without being explicitly coded for the task.
ML is invaluable for data analysis because it can automatically identify patterns and anomalies in large datasets that are often too complex for humans to analyse manually. Its ability to learn from and make predictions on data makes it a powerful tool for a range of applications, from personalising user experiences to predicting market trends or diagnosing diseases. The versatility and adaptability of ML allow for insightful and often more accurate analysis, aiding decision-making across numerous fields.
And by the way, the two paragraphs you just read? They were not written by a human. The explanation was generated by the AI-powered chatbot ChatGPT, after we asked it to explain how machine learning works, and why it is a useful tool for analysing data. In other words, it was a machine learning model that generated the text.
ChatGPT is a language model trained on billions of existing texts, which it uses as a basis to generate completely new content. The model was created by OpenAI and is an openly available tool that you can ask anything—and get a convincing and detailed answer in perfectly good English, or whatever language you want to use (but don’t trust everything it says; at the time of writing, ChatGPT does not have access to information newer than 2021, and it’s created to be convincing—not to provide you with updated, quality-assured facts).
The boundaries of what is possible to achieve with machine learning are currently moving at a breath-taking pace. Machine learning models that can create original photorealistic images, write convincing texts and generate videos based on simple keywords are just a few of the recent breakthroughs, and new advancements can be read about almost every week.
And, yes, as ChatGPT tells us: Machine learning makes it easier and more accurate to analyse large amounts of data.
Insight
Patterns in data
Artificially intelligent systems—and more specifically machine learning—are the driving force behind the explosive increase in the use of data in today’s society, which is leading to more and more being automated and digitised.
However, this does not mean that the technology is speeding ahead totally without human intervention or assistance. As you remember, machine learning is limited and problem-specific. It is up to us humans to ask good questions and define tasks we need help with, and then use machine learning as one of many available aids to find answers and solutions.
The concept of machine learning emerged as early as the 1950s, but it is only on this side of the turn of the millennium—and above all in the very last years—that its development and use have exploded. This is due to two factors. First: Available computing power has increased more or less in line with Moore’s law (which says that the number of transistors in an integrated circuit can double every other year, but which in practice is used to say that it is the computing power in computers that doubles). Second: Access to data has grown at an even faster pace, for reasons you have learned throughout the Data Journey.
And machine learning is essentially about using mathematics and typically also statistics to find patterns in data.
Machine learning itself is also—like artificial intelligence—a kind of umbrella term. There are many subcategories and specialisations within machine learning, such as language processing, computer vision and neural networks.
We will not go into how all this works and is connected, as that would become a completely different course! But let us get to know better what machine learning has to do with statistics.
Classification and linear regression
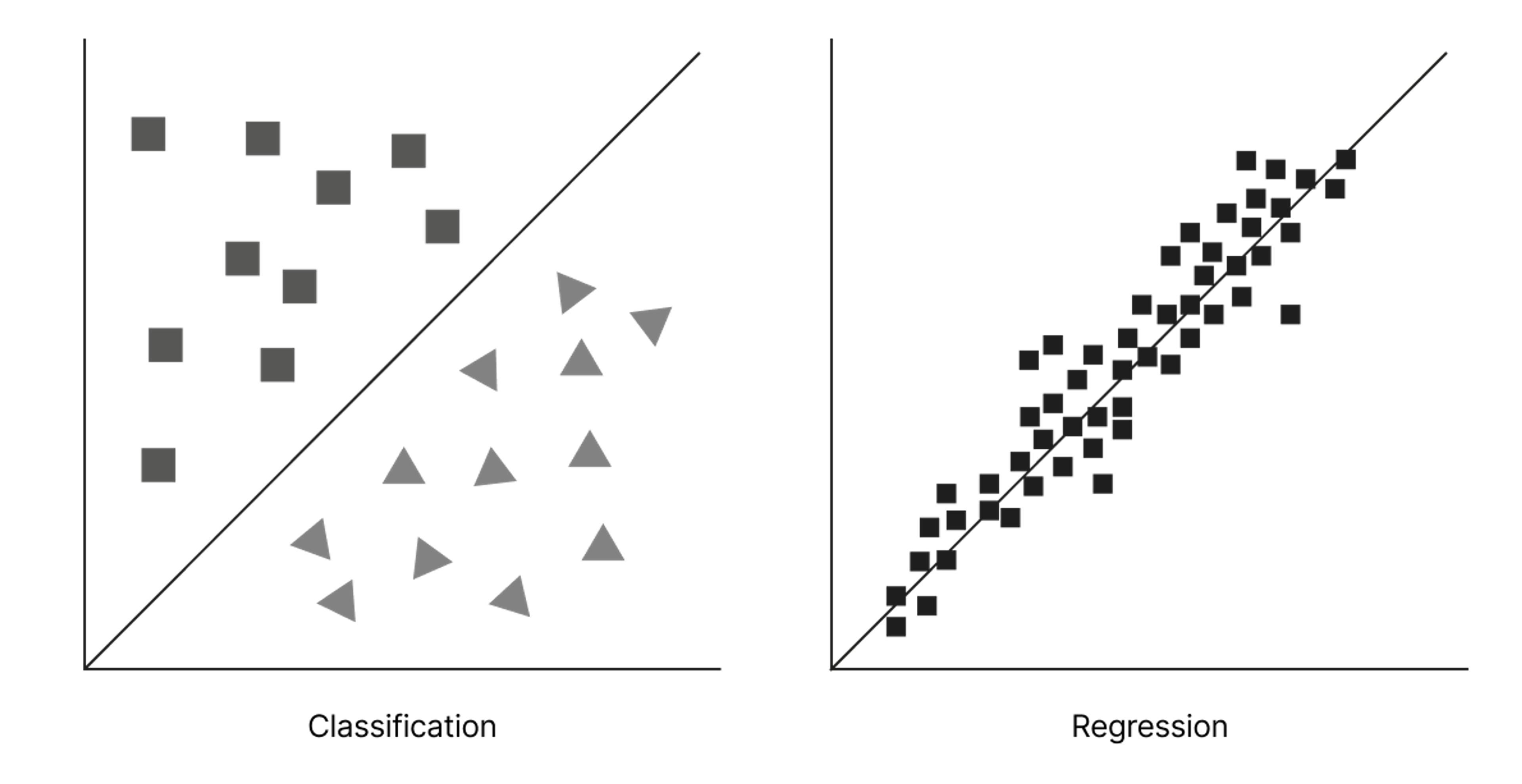
Two important techniques used in machine learning come from statistics and are called classification and linear regression.
Classification
Classification is, as the name suggests, about determining which class an object belongs to.
Have you ever wondered how the spam filter in your email inbox works? Here’s the answer! At least partly. When fraudsters and other unwelcome guests harass your inbox, machine learning models ensure that these emails are classified as junk mail, while work emails and legitimate newsletters are classified as desired information.
Classification is widely used with supervised learning where the classes are predefined. The model should therefore learn to recognise characteristics of objects and sort them into predefined categories. Factors such as unknown sender (never exchanged emails before), when and where the email was sent (in the middle of the night, from an IP address abroad) and keywords like “dollar” can make the model consider it more likely to be spam. But the class “spam” is already defined; the model does not have to figure out itself that junk mail exists or that this is a problem.
Classification comes from statistics, and does not necessarily involve artificial intelligence. However, the advantage of using machine learning for this is that the results can become better and more detailed the more and better the model learns.
With junk mail, fraudsters will always find new methods and become increasingly convincing, making it difficult to catch up with predefined rules. But the more spam a machine-learning spam filter sees and learns from, the better it becomes at identifying junk mail.
Classification can also be used to give you recommendations for movies and series on a streaming service, as we touched on in Chapter 2. And here it might be easier to see why this is actually statistics:
Movies like The Terminator, Blade Runner, Alien and The Matrix will share many characteristics in their descriptions, which distinguish them from Mamma Mia and My Big Fat Greek Wedding. When the streaming service recommends something new to you, it looks for properties and common features in what you watch, and finds new suggestions with the closest possible relationship to these.
Remember, for machine learning models, all of this is just numbers: Start sorting and weighing X number of “dystopian future” against Y number of “kisses and hugs” – plus many, many other variables and rules—and an image will eventually emerge of what you like. Or a statistical correlation, if you will.
Linear regression
Do you remember the trend with colouring books for grown-ups, where you are supposed to draw lines between a bunch of tiny points until an image gradually emerges?
For a true grown-up version of connecting lines between points, you could instead try regression analysis!
Linear regression (which is one of several forms of this kind of analysis) involves just that: drawing a line (a curve or graph) that best describes the relevant data we’re working with. Imagine a graph with an X- and Y-axis, where we plot data as points that scatter around. Perhaps the points align rather perfectly on a line, or along a curve in a predictable pattern. Or perhaps they’re all over the place. We aim to find the line that best fits the data points.
If A, B, C, D, and E are distributed according to a specific pattern along the two axes, a well-fitted model made with linear regression will give us a rather good idea of where F will show up too. We’ve then established a relationship between the variables—for instance, a curve that demonstrates the relationship between population and carbon emissions in different countries.
While classification involves placing an object into a specific class, regression is about assigning a value or number to various outcomes, and then finding patterns and relationships between these. We can say that classification is used to solve categorical problems, and regression is used to solve continuous problems.
Like with classification, this is something we can do perfectly well without machine learning, but that gains superpowers when used with big data and machine learning models. It can help us do nothing less than to see into the future!
Both classification and linear regression are techniques also used in data mining, too, which we’ll look at in the next topic. But first, if you want, you can look in the box below to learn a bit about an exciting part of machine learning we haven’t talked about so far, namely neural networks.
Neural networks and “black box” systems
Artificial intelligence still has a long way to go before it can match human intelligence. For the brain is so intricate, and practically almost impossible to emulate.
Nevertheless, there is a form of machine learning that is inspired by how the human brain works. It’s called neural networks.